Accuracy
Accuracy metrics provided by @UmpScorecards represent the proportion of taken pitches called correctly over a certain subset of taken pitches (a game, a season, etc.). Exactly how we determine whether a pitch was called correctly depends on whether the pitch was thrown during or before the ABS era.
In the ABS era
To determine whether a pitch was called correctly in the ABS era, we mirror the ABS strike zone definition as closely as possible. This means we use each player's officially measured strike zone dimensions, apply no tolerance or margin of error (because ABS seemingly does not), and project each pitch's location to the middle of the plate using pitch trajectory data.
We can't guarantee that our system perfectly replicates the ABS zone on every pitch — on the vast majority of pitches, no challenge is made, so we never observe ABS's ruling. But on the roughly 1,600 pitches challenged during spring training in 2025 and 2026, our system agreed with the ABS decision more than 99.5 percent of the time. In the cases where an ABS decision does not match our model, we take the ABS decision as the ground truth.
Pre-ABS era
To determine if a pitch was called correctly, our Pre-ABS algorithm starts by calculating the likelihood that the pitch was a strike. This is done using a Monte Carlo simulation of a pitch's potential true location, given its reported location and a distribution that represents potential measurement error (both vertical and horizontal) within the Hawkeye tracking system. For each pitch, 500 potential true locations are simulated, and the likelihood that a given pitch is a strike corresponds to the proportion of the pitch's simulated potential true locations that fall within the strike zone. To read about how we determine whether an individual pitch falls within the strike zone, and, more generally, how we determine the size of the strike zone, click here. To learn more about the Hawkeye measurement system and its potential biases, read here.
From there, we consider a taken pitch to be incorrectly called if one of two conditions hold: the probability that the pitch was truly a strike was over 90%, and the umpire called it a ball; the probability that the pitch was a ball was over 90%, and the umpire called it a strike.
The team at @UmpScorecards thinks that this method strikes a good balance between interpretability, validity, practicality, and fairness. Other methods, such as using a harsh cut off at the edge of the zone (what we did when this account was first created), or using a universal 1 inch margin of error past the strike zone, tend to sacrifice at least one of these.
Expected stats
In addition to measuring whether an umpire got a call right, we also estimate how likely a given pitch is to be called correctly by an average umpire — what we call expected accuracy. This lets us distinguish between pitches that are easy to call (a fastball down the middle) and those that are genuinely difficult (a breaking ball that clips the edge of the zone), and evaluate umpires accordingly.
We model expected accuracy in two stages. First, a gradient boosted classifier trained on the previous full season provides a baseline estimate of call difficulty for each pitch. Then, we adjust that estimate using a beta calibration layer fit on a rolling 30-day window of recent games — including spring training at the start of the season. The beta calibrator lets the model adapt to short- and long-term shifts (for instance, umpires generally get better over time) in how the zone is being called without retraining the full model from scratch.
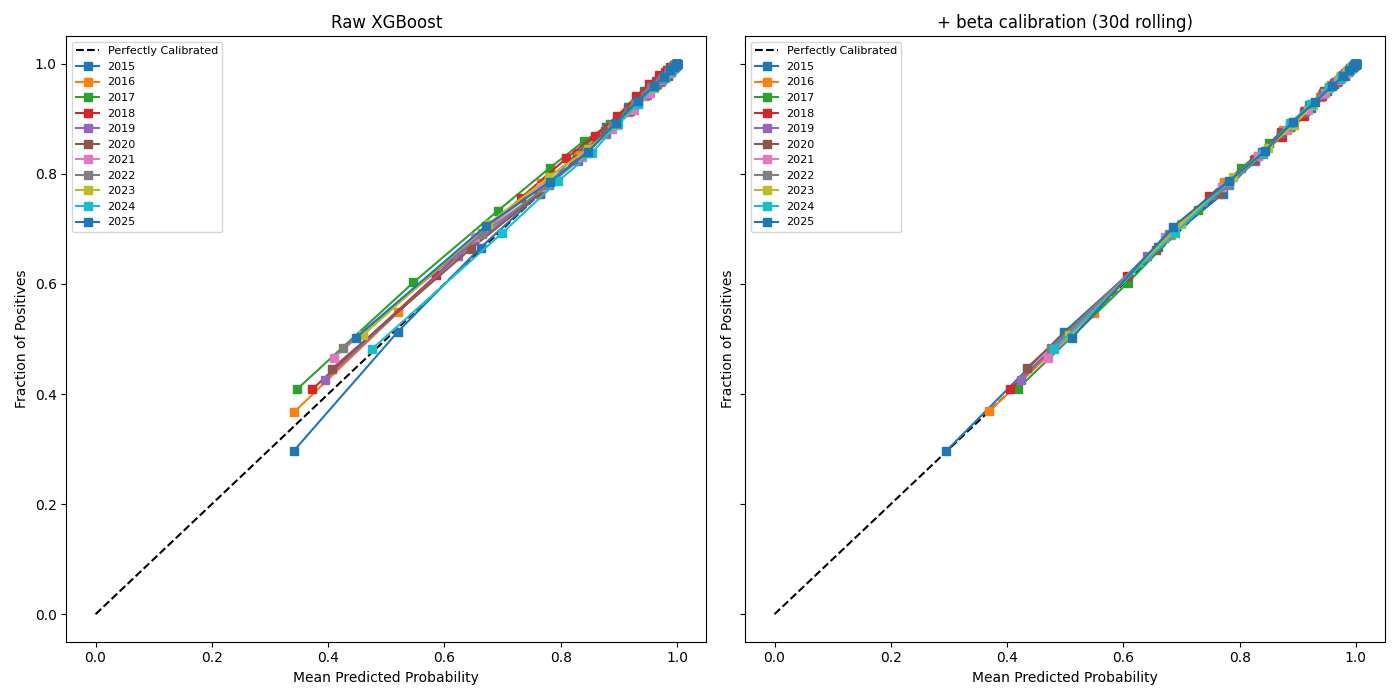
Calibration curves with and without beta smoothing for our classifier model